
A medical AI chatbot purpose-built to support general practitioners in Switzerland
The acceleration of biomedical and clinical breakthroughs has led to unprecedented growth of medical knowledge, posing significant challenges for primary care physicians and specialists to stay updated. Recently, an artificial intelligence (AI)-based knowledge support tool for software engineers tackling complex knowledge-based tasks has been introduced. Microsoft’s Copilot is now extensively used in the industry, assisting both novice and expert programmers.
An AI co-pilot for physicians, designed to navigate the growing body of medical literature, could similarly enhance efficiency and reduce error rates in medical practice. High-performing large language models (LLMs) have accelerated the development of AI chatbots, which are emerging as the preferred tools for accessing and retrieving complex information. Currently, most medical chatbots target patients as their primary users. For example, “One Remission”, Florence, and “Youper” focus on mental health and emotional well-being, while “Babylon Health” provides AI-based primary care consultation services with an option to transition to a live consultation with a physician.
“In a Nutshell“ is an online educational program tailored for Swiss primary care physicians, offering curated, practice-oriented medical guidelines and literature. Through expert curation, this program structures and summarises large volumes of clinically relevant information into concise, efficient reference materials for physicians. To further enhance accessibility, “Ask Dr. Nuts,” a purpose-built medical chatbot trained with the content from “In a Nutshell”, was developed to empower Swiss physicians to efficiently retrieve specific curated medical information through interactive chatbot queries, streamlining the literature review process.
This study evaluated the performance of “Ask Dr. Nuts” (hereafter referred to as the chatbot) as a “co-pilot” for primary care physicians navigating medical literature in daily practice. Between July 28 and October 17, 2023, we collected 1,015 chatbot-user interactions. Each interaction logged the date, time, document context from “In a Nutshell,” and an optional user rating of the chatbot response. Ratings, submitted through the chatbot’s web-based visual interface at the end of each bot response, ranged from 1 (lowest) to 5 (highest). To gather broader user feedback, we distributed a survey (figure 1) via email to all users.
Chatbot-user interactions were classified into “Therapy” and “Diagnosis” categories based on keyword searches in the chatbot’s responses. Interactions containing the strings “therap” or “behand” (“Behandlung”, therapy in German) were assigned to the “Therapy” category, while those with the strings “diagnos” or “ursach” (“Ursache”, diagnosis in German) were assigned to the “Diagnosis” category. Interactions could belong to both categories or be categorised as “Others” if no relevant keywords were detected. Rating frequencies for chatbot interactions that cited “In a Nutshell” content versus those that did not were analysed using a chi-square test.
For the expert evaluation, interactions with a minimum user rating of 3 and responses incorporating “In a Nutshell” content were selected. From the pool of considered interactions, the analysis focused on five medical fields: Diabetology, Haematology and Oncology, Infectiology, Cardiology, and Urology. Up to 10 interactions per field were randomly selected, balancing "Therapy" and "Diagnosis" categories where possible (e.g., 6 for Diabetology, 8 for Haematology and Oncology, and 10 for others). Adjustments to this balance were made to maximise the inclusion of eligible user-chatbot interactions for the expert survey. A panel of expert reviewers1 then evaluated these interactions based on predefined criteria (figure 1).

Figure 1. Questions included in the survey for (a) users and the (b) expert panel.
Physicians primarily interacted with the chatbot between 09:00 and 18:00, corresponding to standard practice hours (figure 2). Most interactions focused on topics related to “Diagnosis” and “Therapy,” with activity peaks observed during the early morning and afternoon.
The top three medical fields for which practitioners sought support were cardiology, infectiology, and urology – fields that are highly relevant in primary care and encompass widespread conditions such as hypertension, chronic coronary disease, influenza, and urinary tract infections. Practitioners queried the chatbot on matters related to “Diagnosis,” “Therapy,” and combinations of both topics (Figure 2). These findings align with the primary role of general practitioners, who often require succinct and reliable information during or in preparation for patient consultations.
Overall, practitioners rated responses containing “In a Nutshell” content significantly higher than chatbot replies without curated information (p < 0.001). Specifically, the proportion of chatbot responses rated four and five stars increased when the chatbot incorporated “In a Nutshell” content. The average rating significantly improved by almost 0.8 points for these responses. The 'Ask Dr. Nuts' chatbot is a pre-trained LLM fine-tuned with nutshell booklets - it may or may not use the provided curated information.
When analysing the primary care physicians’ user experience based on the survey responses (Figure 1), 78.6% (22 out of 28 users) reported trusting the chatbot’s answers (level of trust ≥ 6 on a scale of 1 to 10; figure 2). Additionally, 57.1% indicated they would consult the chatbot again for medical advice, and 53.6% stated they would recommend it to a colleague. These findings indicate that the chatbot is perceived as a trustworthy and useful tool for general practitioners in daily practice. When medical experts evaluated the chatbot's performance using the “Expert User” questionnaire (figure 1), which assessed correctness, completeness, and applicability, they found that the responses were 71% correct, 56% complete, and 81% relevant to daily practice (figure 2).
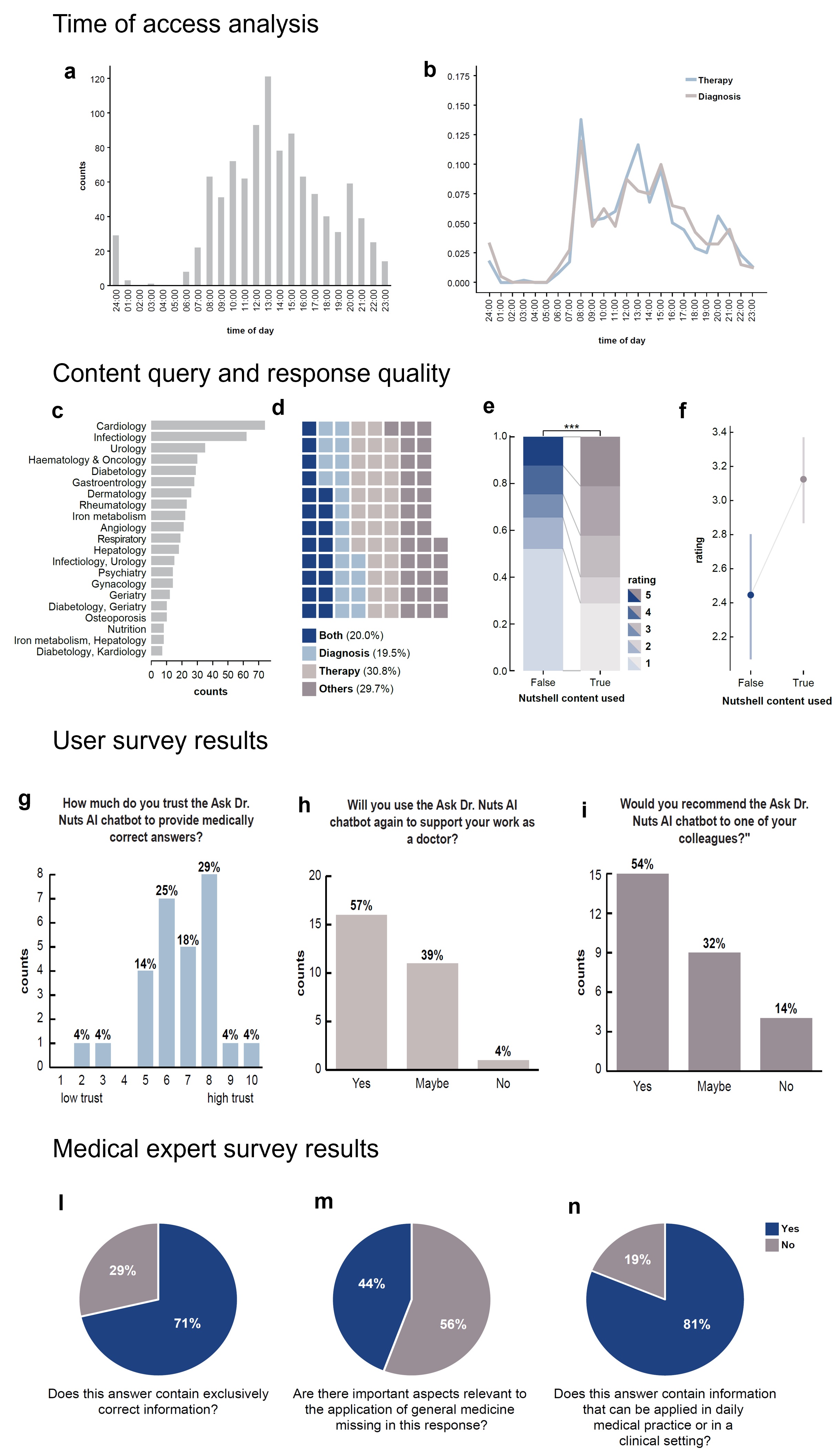
Figure 2. Time of Access Analysis. (a, b) Histograms showing the distribution of user-chatbot interactions over the course of a day, filtered by “Therapy” and “Diagnosis” categories. Interactions predominantly occurred during practitioners' working hours (08:00–18:00). Content Query and Response Quality. (c) A bar chart ranking medical topics queried by users, reflecting common scenarios in general practice. (d) A waffle chart showing the fraction of user-chatbot interactions by category: “Therapy” and “Diagnosis” together account for approximately 60% of interactions, while “Both” and “Others” each contribute 20%. (e) A studded bar chart showing significant differences (p < 0.001, Chi-square test) in user ratings of chatbot responses, comparing those with and without the use of “In a Nutshell” content. (f) User ratings improved significantly when responses included “In a Nutshell” content, with an average increase in mean rating. Dots represent means, and bars indicate 95% confidence intervals. User Survey results. (g–i) Histograms depicting user survey results, showing the proportion of users who (g) trusted the chatbot’s answers, (h) would reuse it for work-related tasks, and (i) would recommend it to colleagues. Bar heights indicate counts per category, with percentages displayed above each bar. Medical Expert Survey. (j–l) Results from the Medical Expert Survey evaluating chatbot responses: (j) 71% of the analysed chatbot answers had exclusively correct information, (k) 56% included all relevant information needed for general practice, and (l) over 80% could be applied to daily medical practice.
Chatbots show significant promise as tools for supporting medical practice, providing primarily correct, though often incomplete, answers. However, their accuracy requires improvement: 25% of responses were found to contain partially incorrect information, and 44% missed valuable details. As AI tools become increasingly integrated into medical practice, the critical question shifts from whether they should be used to how their implementation can maximise benefits for medical professionals. Our investigation highlights the potential of medical AI chatbots to improve primary care while exposing critical gaps that must be addressed before widespread adoption. The stakes are high, as even minor errors could significantly impact patient safety and undermine physicians’ trust in these technologies.
Medical practitioners face the dual task of navigating an ever-expanding body of medical evidence while providing patient care with increasing speed. Due to their rapid processing, comprehensiveness, and human-like interaction capabilities, medical chatbots are well-suited to address these challenges. However, their effectiveness depends on the accuracy of the information they deliver. Our findings underscore the importance of training chatbots using expert-curated medical content. This semi-supervised approach significantly improves correctness and promotes trustworthiness and user satisfaction. Failure to train chatbots on reliable, high-quality data has led to notable shortcomings, such as those observed with Microsoft’s Watson Health.
Given the patient-facing role of medical AI chatbots, transparency and traceability of their responses are essential. The authors recommend that chatbots include hyperlinks in their answers, linking directly to the relevant passages in the literature to enable verification and build user trust.
While our initial results regarding the accuracy of the chatbot are promising, findings from the expert survey reveal considerable room for improvement. Experts determined that over 25% of chatbot responses were at least partially incorrect, and nearly half (44%) lacked potentially valuable information. As medical experts' evaluations currently serve as the gold standard, the medical community should urgently establish benchmark scenarios for the regular and objective assessment of the quality of AI chatbot outputs, especially given their rapid evolution and increasing prevalence.
Interestingly, the detected incompleteness in chatbot responses (44%) contrasts with the perceived usefulness of the information, rated at 81%. This suggests that while the chatbot may serve as a helpful supplement, it cannot yet replace formal clinical practice guidelines. These limitations likely contribute to the observed discrepancy between high user trust in chatbot accuracy and the comparatively lower intention to reuse or recommend the platform to a colleague. Medical professionals are trained to critically evaluate information sources, and even minor inconsistencies or gaps in chatbot responses can reduce user engagement.
Our analysis also highlights discrepancies between user and expert perceptions of chatbot response quality, likely rooted in differing expectations. Users evaluated the chatbot quality based on its utility in primary care during consultations, while experts assessed its accuracy and completeness against specialist knowledge, often exceeding the training content provided to “In a Nutshell” and the granularity required for general practice. Additionally, the low response rate (<10%) to the user survey may introduce bias, skewing results toward a specific sub-demographic and further accentuating differences between expert and user perceptions.
The utility of medical AI chatbots, such as “Ask Dr. Nuts”, depends on the trustworthiness of the information they provide and the ease of knowledge retrieval for users in daily practice, aligning with the initial analogy of a co-pilot. In this respect, the results of the study are promising, with most primary care physicians indicating they would recommend the chatbot to colleagues. However, the study lacks a comparator, such as manual information retrieval using a widely employed digital medical resource like UpToDate. Furthermore, the study was conducted exclusively in German. Although the chatbot appears to provide consistent responses in French and Italian, thorough benchmarking across Switzerland’s dominant languages is necessary to confirm content accuracy and reliability.
The rapid development of medical AI chatbots highlights the urgent need for consensus within the Swiss medical community on two critical issues: first, determining the sources of information with which these chatbots should be trained, and second, establishing criteria to benchmark their performance. In primary care, multiple professional organisations issue guidelines for the same condition. For instance, type 2 diabetes management and blood pressure control for cardiovascular prevention may vary depending on whether guidelines from cardiologists, endocrinologists, or organisations like the American Heart Association or German S3 are followed. Agreeing on a standardised set of guidelines for training chatbots is essential to ensure consistency.
Secondly, the medical community must determine the acceptable level of accuracy and risk for AI tools to be integrated into general practice. Unlike the centuries it took to establish randomised controlled trials as the gold standard for medical interventions, the adoption of AI demands a more rapid but equally rigorous approach. Notably, a recent survey found that an error rate of 11.3% was considered acceptable for human radiologists but only 6.8% for AI programs, reflecting a potential bias against AI systems. Addressing this disparity, the establishment of a standardised benchmarking dataset for medical AI chatbots should be prioritised.
Medical AI chatbots will inevitably become integral to general practice in the coming years. The Swiss medical community must ensure that these tools deliver high-quality medical content tailored to the country’s specific needs. Discussions should focus on the type of training data required (e.g., guidelines, research articles, and expert recommendations) and the performance standards these tools must meet to be deemed clinically acceptable.
Acknowledgements: We thank the members of Prof Dr med. Dr phil. Andreas Wicki’s laboratory and the Pro Medicus team for their critical discussions. We also extend our gratitude to the team at Noser Engineering AG, Winterthur, Switzerland, for training the “Ask Dr Nuts” chatbot according to Pro Medicus' specifications and for providing the authors with the tabulated data for this study.
Conflict of Interest: Dominique Froidevaux serves as Chief Executive Officer and equity owner of Pro Medicus GmbH. The “In a Nutshell” content and the “Ask Dr Nuts” chatbot are proprietary products of Pro Medicus GmbH.
Panel of Experts: We thank Prof Dr Werner Albrich, Dr med. Andreas Jakob, Dr med. Kathrin Bausch, Dr med. Matthias P. Nägele, Prof Dr Jakob R. Passweg, Prof Dr Philip Tarr, and Prof Dr Stefan Toggweiler for their time, interest, and meticulous evaluation of the “Ask Dr Nuts” chatbot responses.
Gabriele Gut, Department of Medical Oncology and Hematology, University Hospital Zurich, Zurich, Switzerland / University of Zurich, Zurich, Switzerland
Tarun Mehra, Department of Medical Oncology and Hematology, University Hospital Zurich, Zurich, Switzerland
Eva Camarillo-Retamosa, Department of Medical Oncology and Hematology, University Hospital Zurich, Zurich, Switzerland
Dominique Froidevaux, Pro Medicus GmbH, Zurich, Switzerland
Andreas Wicki, Department of Medical Oncology and Hematology, University Hospital Zurich, Zurich, Switzerland / University of Zurich, Zurich, Switzerland; andreas.wicki[at]usz.ch